Setting up your Project
Once you got the hang of Python and have installed a code editor such as Visual Studio Code, it is time to start working on your own project and utilise the various tools that greatly improve the quality of a model.
By applying the structure as I write here right from the start, you ensure that anything you build is maintainable and scalable. This is especially important when you want to share your model with others or when you want to use it for a longer period of time.
Managing your Project
Starting a new project starts with creating a new empty folder named after the project, e.g. “FinanceToolkit”. Then, open the folder in your code editor and initialize Git with git init (or pull in a remote repository). I tend to make a connection with a remote repository afterwards through git remote add origin URL so I can commit, push and pull to the branches.
Once this is done, I start including the following files that help manage the project. Within any project of mine these will always be there, in fact I tend to copy them over from the Finance Toolkit repository as it is a great template to start with. This is the case for both personal and professional projects.
This consists of the following files:
- README.md which includes a (short) description of the repository with useful links. This is a file such as the one you are reading right now.
- .gitignore that includes Python specific and module specific exclusions. E.g. think of the exclusion of .idea, .vscode, .venv, .pytest_cache, .DS_Store, etc. See an example here of how such a file could look like.
- pyproject.toml that includes build setups, linter configurations and dependencies (example). This file is the core of the project and contains all necessary information to run the project. It is the successor of the
setup.pyandsetup.cfgfiles. Read more about it in PEP518. - .pre-commit-config.yaml: a special file meant for using
pre-commit. This file is used to configure which linters should be run prior to committing code. It keeps the quality of the code to the highest standard and is therefore definitely a must-have. It can be used by executingpre-commit installin the terminal. See an example file here.
The objective of these files is to lengthen the life span of the model. As an example, if you are still using append in Pandas you haven’t been on top of your package dependencies given that this functionality has been depreciated since January 2022 in v1.4.0. Not being on top of these developments will mean that unless you change the code, you will be stuck on v1.4.0 and subsequently, Python 3.8 and 3.9.
Directory Structure
The folder structure could look like the following, emphasizing here on the financetoolkit folder that contains the actual financial models:
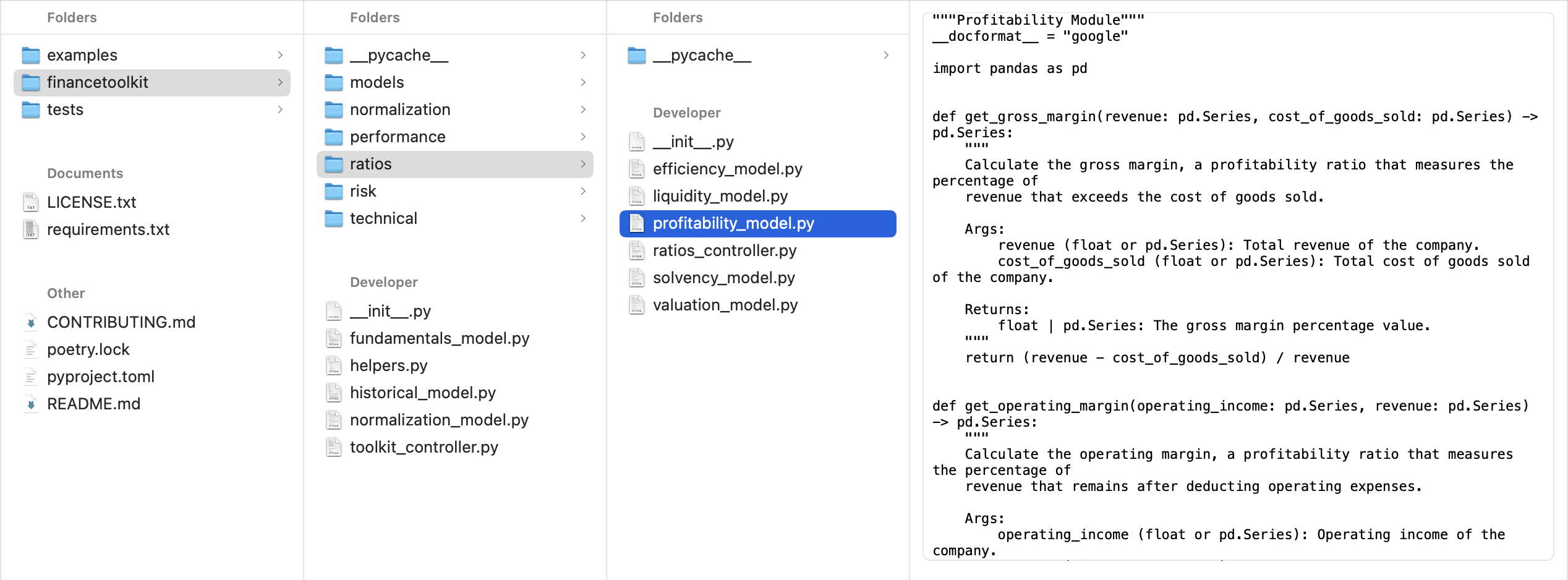
The tests folder structure has the same structure except it contains unit tests for pytest to work with:

There is a lot of room to change this structure, but the most important thing is that the model is structured in a way that is understandable and maintainable not only for yourself but also for others.
As an example, my package the FinanceToolkit follows this exact structure but this is not an isolated case, you will see the same structure in place when you look at a project like OpenBB which is the largest open-source project in the Finance space. There is room to expand this also with _view modules.
In any case, using the above makes it very clear where to find what and what the purpose of each file is as discussed in Structure your Model.
Dependency Management
The chances of your model surviving the next few years goes up significantly if you keep your dependencies up to date. With this, you define what version of Python, Pandas, NumPy, Scipy and more you require at the minimum for the model to function. It would look something like this in the pyproject.toml file:
[tool.poetry.dependencies]
python = ">=3.10, <3.13"
pandas = {extras = ["computation", "performance", "plot"], version = "^2.1.0"}
requests = "^2.31.0"
scikit-learn = "^1.3.1"
[tool.poetry.group.dev.dependencies]
pytest = "^7.4.1"
pylint = "^2.17.5"
codespell = "^2.2.5"
black = "^23.7.0"
pytest-mock = "^3.11.1"
pytest-recording = "^0.13.0"
pytest-cov = "^4.1.0"
ruff = "^0.0.287"
pytest-timeout = "^2.1.0"
pytest-recorder = "^0.2.3"
ipykernel = "^6.25.2"
This uses the dependency manager Poetry, an advanced tool that understands the relationships between each package and their dependencies. It is also able to create a virtual environment for you and install all the dependencies in there. This is a great way to keep your dependencies in check and to make sure that you are not using any deprecated functions. Poetry has extensive documentation and it is therefore recommended to have a look at it here.
Once this is done, you can add dependencies by using poetry add (e.g. poetry add pandas). This will result in pandas being added to [tool.poetry.dependencies]. Then, once all your dependencies are in place, it simply requires poetry install to install all the dependencies in the virtual environment. This will also create a poetry.lock file which is a snapshot of all the dependencies and their dependencies. This is a great way to keep track of what is installed and what is not.
Pro-tip: needing to be aware of new versions of each package can be tedious. Therefore, consider looking at extras as defined with Pandas. These include most of the data wrangling required and therefore limits maintenance for yourself. See here.
Next to that, there is a section called [tool.poetry.group.dev.dependencies] which are dependencies only relevant for development. You only want to install dependencies that are required for your model to be able to execute as a user. As a developer, these dependencies are required to be able to run tests, linting, etc.
Why Poetry over requirements.txt or pip?
Poetry is an actual dependency manager that understands the relationship between each package. This is different from requirements.txt which simply lists the packages and won’t stop you from installing a package that is not compatible with the other packages. Pip is a package installer and not a dependency manager which is therefore not recommended to maintain an environment. There are other solutions available as well like pipenv which you could also use but I prefer Poetry especially as it is increasing in popularity.
To give you an idea what it would look like:
(modelling) FinanceToolkit % poetry install
Installing dependencies from lock file
Package operations: 72 installs, 0 updates, 0 removals
• Installing six (1.16.0)
• Installing asttokens (2.4.1)
• Installing executing (2.0.0)
• Installing idna (3.4)
• Installing multidict (6.0.4)
• Installing parso (0.8.3)
• Installing platformdirs (3.11.0)
• ...
Installing the current project: financetoolkit (1.6.1)
And in case I wish to add a new dependency (in this case including extras)
(modelling) FinanceToolkit % poetry add pandas --extras "computation performance plot"
Using version ^2.1.2 for pandas
Updating dependencies
Resolving dependencies... (1.6s)
Package operations: 15 installs, 0 updates, 0 removals
• Installing pytz (2023.3.post1)
• Installing tzdata (2023.3)
• Installing contourpy (1.2.0)
• Installing cycler (0.12.1)
• Installing fonttools (4.44.0)
• Installing kiwisolver (1.4.5)
• Installing llvmlite (0.41.1)
• Installing pandas (2.1.2)
• Installing pillow (10.1.0)
• Installing pyparsing (3.1.1)
• Installing bottleneck (1.3.7)
• Installing matplotlib (3.8.1)
• Installing numba (0.58.1)
• Installing numexpr (2.8.7)
• Installing xarray (2023.10.1)
Which will then show up in the pyproject.toml file:
[tool.poetry.dependencies]
python = ">=3.10, <3.13"
pandas = {extras = ["computation", "performance", "plot"], version = "^2.1.2"} <-- Added
requests = "^2.31.0"
scikit-learn = "^1.3.1"
Setting up Linters
Linters are scripts that check and improve your code. This can be anything from formatters to spell checkers to code quality checkers. The following are recommended to always apply and ensure that no code is committed through Git that do not meet these requirements:
- Black which is a PEP 8 compliant opinionated formatter, maintained by the developers of Python themselves.
- Ruff is a linter that is extremely fast and replaces Flake8 (plus dozens of plugins), isort, pydocstyle, yesqa, eradicate, pyupgrade, and autoflake.
- Pylint which checks for errors, enforces a coding standard, looks for code smells, and can make suggestions about how the code could be refactored.
- mypy which is a type checker that helps ensure that you’re using variables and functions in your code correctly in accordance with PEP 484.
- bandit which is designed to find common security issues in Python code.
- codespell which signals common misspellings in text files.
These linters can be configured inside the pyproject.toml as seen below:
[tool.ruff]
line-length = 122
select = ["E", "W", "F", "Q", "W", "S", "UP", "I", "PD", "SIM", "PLC", "PLE", "PLR", "PLW"]
ignore = ["S105", "S106", "S107", "PLR0913", "S310", "S301"]
exclude = ["conftest.py"]
[tool.pylint]
max-line-length = 122
disable = ["R0913", "W1514", "R0911", "R0912", "R0915", "R0801", "W0221", "C0103", "E1131"]
[tool.ruff.isort]
combine-as-imports = true
force-wrap-aliases = true
[tool.isort]
profile = "black"
line_length = 122
skip_gitignore = true
combine_as_imports = true
[tool.codespell]
ignore-words-list = 'te,hsi'
skip = '*.json,./.git,pyproject.toml,poetry.lock,examples'
[tool.mypy]
disable_error_code = "misc"
The .pre-commit-config.yaml file is meant to configure which linters should be ran prior to committing code. By running pre-commit install, it will install the linters based on this file.
I recommend downloading this .pre-commit-config.yaml file and use it as a template for your own projects. You can definitely deviate from it as you like but this is a great initial template to get you started and it uses the most common linters.
With this file installed, it will automatically be ran on each commit. E.g. when running a commit, it could look like the following:
(base) FinanceToolkit % git commit -m "v1.5.0 Release featuring Threading"
check for merge conflicts................................................Passed
detect private key.......................................................Passed
black....................................................................Failed
- hook id: black
- files were modified by this hook
reformatted financetoolkit/fundamentals_model.py
All done! ✨ 🍰 ✨
1 file reformatted, 1 file left unchanged.
ruff.....................................................................Failed
- hook id: ruff
- exit code: 1
financetoolkit/helpers.py:75:33: PLR2004 Magic value used in comparison.
Found 1 error.
codespell................................................................Passed
mypy.....................................................................Passed
pylint...................................................................Passed
Based on the files I have added to my commit, I am able to see which linters have passed and which have failed. In this case, Black and Ruff have failed. This is because Black has reformatted the code and Ruff has found a magic value in the code it is asking me to change. There are multiple things I can do with this:
- I can add a new variable that saves this magic value as the issue is that I use an integer that has little meaning to the reader. This is the preferred way as it makes the code more readable.
- I can add
# noqato the line that is causing the issue. This is mostly relevant if the code remains self explanatory. E.g. let’s say you want to see if the dataset features a single or multiple columns, you could useif len(df.columns) == 1: # noqaas it is clear what the code does. - I can add an exception to the
pyproject.tomland.pre-commit-config.yamlfiles to ignore this specific error. This is not the preferred way as it does not solve the issue but rather hides it. However, in some cases it could be that it is not a big deal that it does.
Once everything has been resolved, it is possible to commit the code. The beauty of this is that code will always be tested before it is committed.
(base) FinanceToolkit % git commit -m "v1.5.0 Release featuring Threading"
check for merge conflicts................................................Passed
detect private key.......................................................Passed
black....................................................................Passed
ruff.....................................................................Passed
codespell................................................................Passed
mypy.....................................................................Passed
pylint...................................................................Passed
[main eb9140d] v1.5.0 Release featuring Threading
5 files changed, 683 insertions(+), 729 deletions(-)
Creating a Git Workflow
While working on code, it is important to follow a solid Git workflow that separates development from production. I make the distinction between working alone or working in a team here because you shouldn’t over complicate things. Needing to approve your own PRs from the Feature branch is non-sense if you are the only one working on the project.
I highly recommend Git even if you have no intention to publish the code, GitHub for example allows the creation of Private Repositories to accommodate for this. The reason you should still use Git is because you can easily revert back to previous versions of the code if you made a mistake or wish to create multiple versions of the code.
My usual approach contains at least the following branches:
- Main: this is your production branch and should only contain versions of the code that are fully production-ready. You should not push directly to main but rather merge from a development branch.
- Develop: this is your development branch and should contain the latest version of the code that is not yet production-ready. You should only push directly to this branch if you are the sole programmer. Otherwise, merge from a feature branch.
This results in the following structure:
If you are working in a team, it is important to have a proper workflow with code reviewers and testers before anything is merged into the development branch to prevent issues from occurring in a feature branch from someone else that is not related to the code changes. The following branches should be included:
- Feature: these are your feature branches and should contain the code that you are working on. It will push to the development branch through PRs. These contain many different feature branches based on the feature that is being worked on and is dropped once the feature is merged into the development branch. For simplicity sake, in the graph below I merged the feature branches into one but in reality, there are many more.
- Hotfix: this is your hotfix branch and should contain the code that is required to fix a bug in production. This is only used in the rare case that a bug is found in production and needs to be fixed immediately.
This results in the following structure:
This is my way of doing things but there are many other ways to do this. The most important thing is that you have a workflow in place that works for you and your team and makes a proper distinction between production and development.
Adding Git Exceptions
The .gitignore file is meant to exclude or include files for Git which comes in very handy when you have Jupyter Notebooks you use for testing or specific data files that contain personal information. This file is only relevant if you apply version control but that should be a given. If it isn’t, definitely look into applying Git for your models as it is a very powerful tool to keep track of changes and to revert back to previous versions.
Such a file could look like the following:
# FinanceToolkit Specific
*.ipynb
!examples/*.ipynb
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
.DS_Store
.ipynb_checkpoints/
.DS_Store
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
Once you have done these steps it’s time to start structuring your model. Visit Structure your Model to continue!